
Możesz jeszcze zobaczyć: wpisać w uruchom msconfig=>uruchamianie=>zaawansowane opcje=>liczba procesorów, powinno być odznaczone pole
- Welcome to BOINC@Poland.
Aktualności:
Nasza strona na Facebooku - poleć znajomym.
Ta sekcja pozwala Ci zobaczyć wszystkie wiadomości wysłane przez tego użytkownika. Zwróć uwagę, że możesz widzieć tylko wiadomości wysłane w działach do których masz aktualnie dostęp.
#82
Archiwum / Odp: ATI HD6000 Series
21 Listopad 2010, 13:30
To co w ostatnich postach napisałem zaczyna się potwierdzać:

#83
Archiwum / Odp: Ciemna materia odnaleziona?
20 Listopad 2010, 14:10Cytat: Troll81 w 20 Listopad 2010, 13:51
taaaaa. przez jaką część sekundy udało się go utrzymać??
Nie podają dokładnie, ale wystarczająco długo by przeprowadzić badania co do tej pory było niemożliwe ;)
CytatThis is the first time that scientists have been able to trap antihydrogen atoms for a long enough time to study them, keeping them at 9 degrees kelvin (-443.47 degrees Fahrenheit, -264.15 degrees Celsius), suspended in a magnetic field inside this Ghostbusters-style machine.
#84
Archiwum / Odp: Najszybszy komputer świata
20 Listopad 2010, 14:04
Krótka prezentacja:
http://www.nvidia.com/content/PDF/sc_2010/theater/Keane_SC10_wed.pdf
http://www.nvidia.com/content/PDF/sc_2010/theater/Keane_SC10_wed.pdf
#85
Archiwum / Odp: Ciemna materia odnaleziona?
20 Listopad 2010, 13:37
Już niedługo nie będziemy się przejmować rachunkami za prąd :parrrty:
Nowe źródo energi, Panowie z CERN ujarzmili antywodór :D
http://gizmodo.com/5692614/antimatter-trapped-for-the-first-time
Nowe źródo energi, Panowie z CERN ujarzmili antywodór :D
http://gizmodo.com/5692614/antimatter-trapped-for-the-first-time
#86
Rozmowy nieBOINCowane / Odp: Na wesolo -
20 Listopad 2010, 13:08
W szczególności dla krzyszp bo odwala kawał dobrej roboty z serwerem statystyk i dla wszystkich innych zaangażowanych w prace. Na polepszenie humoru :respect:


#87
PrimeGrid / Odp: The Leonids Challenge 17.11.2010 18:00 UTC – 18.11.2010 18:00 UTC
17 Listopad 2010, 16:22
To już dzisiaj??!! czemu nikt nie krzyczy ;)
#88
Archiwum / Odp: Phenom II X6 vs Intel Core i7
12 Listopad 2010, 17:29
Nie znalazłem jeszcze testu cpu z boinc, lepsze coś niż nic ;)



http://techreport.com/articles.x/18799/13
http://techreport.com/articles.x/18799/13
#89
Nieskategoryzowane / Odp: Constellation
10 Listopad 2010, 12:57
Czym ten projekt się zajmuje? Na forum wygląda tak że jest na etapie wybrania symulacji jaka będzie przeprowadzana.
#90
Archiwum / Odp: ATI HD6000 Series
10 Listopad 2010, 12:46Cytat: goofyx w 10 Listopad 2010, 12:36Cytat: S6X w 10 Listopad 2010, 12:31Co na tym liczysz i ile pkt/dobę masz?
8800gt sprzedam, wracając do tematu przypuszczalna specyfikacja:
Cayman XT
- VLIW4 Architecture
- 30 SIMD: 1920 SP
- 96 TMUs
- 6 Modules
- * 1 Tessellator/Module
- * 5 SIMDs/Module
- * 16 TMUs/Module
- 4x 8 ROP
- 4x 64-bit GDDR5+ Memory Controller
http://global.hkepc.com/forum/viewthread.php?tid=1526035&extra=page%3D1&page=5
Na 8800gt liczyłem gpugrid,pkt dawało mało tyś. może kilka tyś. (nie liczyłem 24/7) Punktomaniacy nie liczą gpugrida
#91
Archiwum / Odp: ATI HD6000 Series
10 Listopad 2010, 12:31
8800gt sprzedam, wracając do tematu przypuszczalna specyfikacja:
Cayman XT
- VLIW4 Architecture
- 30 SIMD: 1920 SP
- 96 TMUs
- 6 Modules
- * 1 Tessellator/Module
- * 5 SIMDs/Module
- * 16 TMUs/Module
- 4x 8 ROP
- 4x 64-bit GDDR5+ Memory Controller
http://global.hkepc.com/forum/viewthread.php?tid=1526035&extra=page%3D1&page=5
Cayman XT
- VLIW4 Architecture
- 30 SIMD: 1920 SP
- 96 TMUs
- 6 Modules
- * 1 Tessellator/Module
- * 5 SIMDs/Module
- * 16 TMUs/Module
- 4x 8 ROP
- 4x 64-bit GDDR5+ Memory Controller
http://global.hkepc.com/forum/viewthread.php?tid=1526035&extra=page%3D1&page=5
#92
Archiwum / Odp: ATI HD6000 Series
10 Listopad 2010, 12:09Cytat: Tomasz R. Gwiazda w 10 Listopad 2010, 08:40
rozumiem ze juz kase odkladasz ? :) bo jestes najaktywniejszym obserwatorem/newsmanem od nowych kart ATI :)
Mój 8800gt jest już troszkę leciwy, więc jakiś upgrade planuje... ;)
#93
Archiwum / Odp: ATI HD6000 Series
09 Listopad 2010, 22:54
6990 niestety zalicza opóźnienie na Q1 2011
Pozostaje nam czekać na 6970/50 :attack:
Cytat"Antilles"
Market: Discrete GPUs
What is it? AMD Radeon™ HD 6000 Series graphics card for ultra-enthusiasts that will feature two GPUs on one board.
Planned for introduction: Q1 2011
Pozostaje nam czekać na 6970/50 :attack:
Cytat"Cayman"http://blogs.amd.com/work/fadcodenames/
Market: Discrete GPUs
What is it? Second-generation DirectX® 11-capable GPU to launch in the "Northern Islands" family, will be branded AMD Radeon™ HD 69XX graphics processors.
Planned for introduction: Q4 2010
#94
Archiwum / Odp: GT300
09 Listopad 2010, 17:16
Wygląda że gtx 580 to fermi w 100% (wszystko odblokowane + wyższe takty) i do liczenia się nada ;)
CytatNie jest prawdą, że układ GTX-a 580 pozbawiono elementów typowych dla kart z serii Tesla. Wszystkie dodatkowe funkcje, takie jak ECC, nadal ,,siedzą" w układzie GF110 i nie powinno być problemu z wprowadzeniem nowej serii Tesli opartych na tym układzie.http://pclab.pl/art43801.html
#95
Archiwum / Odp: Ostrzeżenie dla użytkowników Aviry
09 Listopad 2010, 15:55
Nic takiego nie zauważyłem ale dzięki za ostrzeżenie.
#96
Archiwum / Odp: ATI HD6000 Series
09 Listopad 2010, 15:34
Testy OpenCL: General Purpose Computing Benchmark 6970:
http://itbbs.pconline.com.cn/diy/12101175.html
Wyniki gorsze niż 5870, problemy ze sterownikami?? %)
http://itbbs.pconline.com.cn/diy/12101175.html
Wyniki gorsze niż 5870, problemy ze sterownikami?? %)
#97
Archiwum / Odp: ATI HD6000 Series
05 Listopad 2010, 21:21
Zmierzyłem linijką na szybko szerokość wtyczki 6pin i wyszło 14mm czyli karta powinna mieć ok 27cm
5870=28cm
5970=32cm
5870=28cm
5970=32cm
#98
Archiwum / Odp: Kto zamknął watek o PNT ? Uzurpator?
05 Listopad 2010, 19:32CytatKrótko:
kto chce to niech przychodzi do Polish National Team i tworzy nową jakość i oddycha świeżym powietrzem. Kto nie chce, niech dalej liczy w drużynie BOINC@Poland.
Jest to komunikat ostatni, sumujący całość sprawy
Pozdrawiam Peciak
Na tym rozmowy się zakończyły.
#99
Archiwum / Odp: ATI HD6000 Series
05 Listopad 2010, 19:27
Jak ktoś poda długość wtyczki 6 i 8 pin gpu to będzie można oszacować długość :)

#100
Archiwum / Odp: ATI HD6000 Series
05 Listopad 2010, 18:48
To jest 6970 ;) na osiągi trzeba jeszcze poczekać



#102
Archiwum / Odp: Polish National Team
01 Listopad 2010, 21:37Cytat: Tomasz R. Gwiazda w 01 Listopad 2010, 20:56
Grzegorzu takie moje zdanie podsumuwania
Cel , idea, wizja - BARDZO SLUSZNA
wykonanie, sposob zakomunikowania "propozycji" na zenujaco niskim poziomie.
Znamy sie nie od dzis i wiesz jakie bylo wczesniejsze stanowisko B@P na roznego rodzaju propozycje polaczenia.
Zamiast miec to na uwadze , wiedzac ze to delikatny i drazliwy temat, po raz kolejny "wasza" metoda jest proba rozbicia wewnetrznego B@P
W ten sposob ciezko cos wspolnie budowac
Poza tym mysle ze 100x prosciej/latwiej i bez straty bylo by zrobic tak ze to B@P zmienia nazwe i reszta chetnych sie do niego przylacza
dla wielu byloby to prostsze i latwiejsze do zaakceptowania
Popieram w 100%
Cytat: Grzegorz Granowski w 01 Listopad 2010, 20:59
Tomasz skopiuję mój wceśniejszy post, uważam będący kwintesencją moich odczuć
apohawk napisał:
Jakbyście chcieli tworzyć naprawdę narodowy zespół, to odezwalibyście się do wszystkich zespołów, a tak olaliście największy zespół i zrobiliście team w 10 osób. Teraz jeszcze przychodzicie z pretensjami.
Może to nasza cecha narodowa, że połączyć potrafiła dopiero nienawiść do innych Polaków, w tym wypadku do B@P. Cóż, każdy naród ma taki national na jaki zasługuje...
EDIT
Może jakbyście mieli coś więcej do zaoferowania niż "rozwalić B@P", to było by o czym rozmawiać.
apohawk a dziwisz się??? w marcu rozpoczęliśmy projekt MPTA, idea szczytna, dobra, dobrze sobie radzaca w rywalizacji z bardzo mocnymi druzynami,
daliśmy odnośnik do Waszej strony, informację o tym, ze współtworzycie sojusz, i co???
i chcialoby się powiedzieć g.... co chciałoby się powiedzieć,
zostało to zupełnie przez Was olane,
PNT jest próbą wyjścia z obecnego stanu stagnacji, tzn. B@P moze i kiedyś był miejsce, które było rozwijane przez wielu z chęcią i przyjemnością?
natomiast teraz to mój odbiór jest taki, że wszyscy mają B@P całować po nie powiem czym, bo jest najwiekszy, z długą tradycją i we wszystkiem jest naj,
strona najlepiej spozycjonowana, wiki najlepiej rozwinieta
jak jest wszystko naj to nie che się nikomu z pasją i oddaniem pracować nad rozwojem,
PNT nie ma wszystkiego naj, natomiast wszyscy bardzo się bedziemy starać, zeby móc dościgną kiedyś druzyny jak Seti>usa czy Seti Germany
i w tej nadziei budowania czegoś pieknego i wiekliego zasadza się siła Polish National Team,
wg mnie w członkach B@P tej pasji i nadziei na coś niowego nie ma
Pozdrawiam,
Grzegorz Granowsk
Cały czas do drużyny dołączają nowi użytkownicy a wraz z nimi nowe pomysły na urozmaicenie sceny boinc.
Jak chcecie być traktowani poważnie to traktujcie inne osoby z należytym szacunkiem.
A tak wrażenia po 1 poście miałem takie: Siema chłopaki stworzyliśmy z ziomalami zajefajny nowy narodowy zespół jeżeli chcecie się bawić razem z nami w piaskownicy to musicie dołączyć bo inaczej będziecie be... nie tędy droga.
Ideę stworzenia jednego mocnego zespołu będę zawsze popierał (i popierałem :) ) żeby nie było że jestem nastawiony przeciwko Wam (PNT).
Namawiacie by do Was dołączyć a chwile później atakujecie B@P i podburzacie tych których chcieliście zwerbować. Nawet jak odpowiadacie na atak to powinniście być mądrzejsi i nie dać się tak łatwo prowokować bo kłótnie do niczego nie prowadzą. Sytuacja wygląda identycznie jak przy wcześniejszych rozmowach na podobny temat czyli nikt nie wyciągnął wniosków. :shame:
#103
Archiwum / Odp: GT300
31 Październik 2010, 11:12
Ciekawa informacja o gtx 580 :wth:
Ogólnie nowy dziforce będzie tylko do granie nie do liczenia.
http://www.nordichardware.com/news/71-graphics/41570-the-geforce-gtx-580-mystery-is-clearing.html
CytatGF110 focuses on retail, without HPC functions
We have had a hard time seeing how NVIDIA would be able to activate its sixteenth SM unit without severe problems with the power consumption. But with GF110 NVIDIA made an active choice and sacrificed the HPC functionality (High Performance Computing) that it talked so boldly about for Fermi, not only to make it smaller but also more efficient.
According to sources to NordicHardware it can be as many as 300 million transistors that NVIDIA has been able to cut in this way. The effect is that GF110 will be a GPU targetting only retail and will not be as efficient for GPGPU applications as the older siblings of the Fermi Tesla family. Something few users will care about.
Ogólnie nowy dziforce będzie tylko do granie nie do liczenia.
http://www.nordichardware.com/news/71-graphics/41570-the-geforce-gtx-580-mystery-is-clearing.html
#104
Archiwum / Odp: ATI HD6000 Series
30 Październik 2010, 15:14
Niestety w języku ojczystym jest ciężko coś znaleźć:
5VLIW= 4 proste operacje + 1 specjalna, proste operacje to np. gry i single precision, specjalna to np double precision
5870 2.72 Tflops gdzie 1/5 stanowi wydajnośc w dp czyli 2.7:5=0.544 Tflops. Problem jest taki że trudno zaciągnąć wszystkie procesy strumieniowe do jednoczesnej pracy. Może sesef mógłby coś powiedzieć na ten temat i jakie potencjalne korzyści można otrzymać z 4VLIW gdzie mamy 4 średnie procesy strumieniowe. Dla boinc-maniaków najważniejszy jest współczynnik ratio sp do dp dla 5VLIW wynosi 1:5 a dla 4VLIW 1:4. Gdyby radek 5870 miał nową arch. to 2.72:4=0.68 Tflops w dp. Gdyby 6970 miał wydajnośc 4 Tflopsów to w dp miałby 1 Tflops (czytaj więcej niż 5970 :respect: ) nie wspomne o 6990 :attack:
CytatWprowadzamy nowe pojęcie, 5 wątkowy, superskalarny procesor shaderowy. Układ AMD/ATI posiada 64 takie procesory. W każdym z nich znajdziemy 5 procesorów strumieniowych (SP), przy czym 4 wykonują operacje proste, a jeden specjalne. Problem w tym, że każdy SP wchodzący w skład procesora shaderowego może wykonywać tylko jeden wątek rozbity równolegle na 5 procesorów strumieniowych. Oznacza to, że R600 w jednym takcie zegara może wykonywać maksymalnie 64 wątki. To jeszcze nie koniec skomplikowanej architektury. Procesor Shaderowy u AMD pracuje w trybie VLIW (Very Long Instruction Word), pozwalającym rozbić jedną instrukcję na 5 równoległych operacji pod warunkiem, że operacje te nie są od siebie zależne.http://www.in4.pl/recenzje.htm?rec_id=413&rectr_str_numer=2
CytatActually it is already known how the VLIW4 units will be organized. The codepath for that arch in the driver is functional since Catalyst 10.4, I've posted some stuff about that over at B3D 10 days ago.http://www.xtremesystems.org/forums/showthread.php?t=261195&page=14
The transcendental functions are done by the xyz units working together (just like it is done for double precision already now, only that it takes 3 slots), so 3 of the 4 slots of the VLIW unit are used to calculate a transcendental. The fourth slot (w) does not take part in that and is still free to use in the same cycle. That means a good part of the t unit got split up in three parts and is distributed to the x, y and z units.
Another function of the t unit was doing format conversions and roundings. This functionality got replicated to all subunits. That means for this kind of stuff Cayman will fly.
24bit integer arithmetics are now fully supported by Cayman and can be done in all 4 slots (Evergreen had only partial support which was not really used).
A 32Bit integer multiplication will unfortunately block all 4 slots (could be done by the t unit with the xyzw slots free for use by other instructions in Evergreen), but this is probably the price to pay to get some transistor savings from the change.
All other integer instructions can again be done in all 4 slots (as before).
Double precision instructions behave the same way as in Cypress. Everything involving a multiplication (MUL, FMA) takes 4 slots while the other stuff (like ADD and conversions) takes 2 slots. That means the DP:SP ratio is 1:4.
5VLIW= 4 proste operacje + 1 specjalna, proste operacje to np. gry i single precision, specjalna to np double precision
5870 2.72 Tflops gdzie 1/5 stanowi wydajnośc w dp czyli 2.7:5=0.544 Tflops. Problem jest taki że trudno zaciągnąć wszystkie procesy strumieniowe do jednoczesnej pracy. Może sesef mógłby coś powiedzieć na ten temat i jakie potencjalne korzyści można otrzymać z 4VLIW gdzie mamy 4 średnie procesy strumieniowe. Dla boinc-maniaków najważniejszy jest współczynnik ratio sp do dp dla 5VLIW wynosi 1:5 a dla 4VLIW 1:4. Gdyby radek 5870 miał nową arch. to 2.72:4=0.68 Tflops w dp. Gdyby 6970 miał wydajnośc 4 Tflopsów to w dp miałby 1 Tflops (czytaj więcej niż 5970 :respect: ) nie wspomne o 6990 :attack:
#105
Archiwum / Odp: ATI HD6000 Series
29 Październik 2010, 19:13
A jednak... ;D 4VLIW (dla przypomnienia 5VLIW posiadają 2xxx=3xxx=4xxx=5xxx=6870/50). AMD wywala ATI z loga i wprowadza największą zmianę w architekturze GPU (amd/ati) w ostatnich latach ?!!! :fright: :respect: Już nie mogę się doczekać 6970 vs gtx 580, święta będą ciepłe w tym roku XD


#106
Archiwum / Odp: Zapytanie o dobór płyty i ram do Phenom`a II 810
26 Październik 2010, 17:28Cytat: 33oliver w 25 Październik 2010, 11:09
Czy do ASRock M3A785GXH/128M i Noctua NH-D14 potrzebne jest dokupienie backplate`u?
Nie (a w przyszłości jak zmienisz socket, to noctua wyśle za darmo backplate umożliwiający montaż chłodzenia na płycie :respect: )
http://www.noctua.at/main.php?show=compatibility_gen&products_id=34&lng=en
#107
Archiwum / Odp: ATI HD6000 Series
26 Październik 2010, 17:18
No to bawimy się dalej, czas na Caymana ;)



Premiera 8 listopada???? ;D

Premiera 8 listopada???? ;D
CytatPS. Čmuchám, čmuchám ...něco se nám chystá na 8.11.2010! - Kdopak to uhodne?
#108
PrimeGrid / Odp: GPU w Proth Prime Search (Sieve)
24 Październik 2010, 14:38
Brook/CAL jest mało popularny (chyba że się mylę , programistą nie jestem XP ) przez to bez przyszłości. AMD mocno promuje Opencl ze względu na uniwersalność (działa na AMD/Nvidia gpu). Problem jest taki że trudno napisać program który będzie stabilny na AMD/OpenCL a nie mówię o wydajności.
Pod tym wzgędem AMD jest daleko w tyle względem Nvidi i nie wiem czy nawet SDK 2.3 coś tu zmieni.

Pod tym wzgędem AMD jest daleko w tyle względem Nvidi i nie wiem czy nawet SDK 2.3 coś tu zmieni.
#109
PrimeGrid / Odp: GPU w Proth Prime Search (Sieve)
24 Październik 2010, 13:29
Z tym happy to bym nie przesadzał :(
CytatOpenCL certainly seems limited compared to native algorithms as with CUDA on the NVidia cards. Have you thought much about trying to do the app in ATI's native Brook/CAL?Przypadkiem nie jest że panowie od gpugrid też nie dają sobie rady :wth:
Yes.
The Collatz project was able to do their app that way, but I have no idea how difficult it is to work with the ATI cards this way...
Well, I couldn't do it without buying an ATI card, and I don't want to buy an ATI card if it's going to be slower than an nVIDIA card. Catch-22!
Also, the current fastest algorithm on nVIDIA is very linear. ATI needs instruction-level parallelism, and evidently that's not easy to come by. So I'm not sure CAL could do much either. Certainly not sure enough to buy an ATI card.
On the other hand, the vectorizing I did on ATI only gave about a 33% speedup. It might be worth un-vectorizing it and applying the newest algorithm. But ATI/OpenCL is so unpredictable that I'm not inclined to try this soon.
#110
Archiwum / Odp: Kandydaci do samorządu
22 Październik 2010, 12:40
Mina kolesia jak się dowiedział że występuje na żywo=> bezcenne |-?
#111
Archiwum / Odp: ATI HD6000 Series
22 Październik 2010, 12:36Cytat: Krzysiak_PL_GDA w 22 Październik 2010, 11:51
Na 99% nowe karty nie posiadają modułu podwójnej precyzji
w pewnym stopniu jest to logiczne skoro są to karty linii HD5770
AMD starało się uzyskać jak najmniejszą powierzchnie więc brak podwójnej precyzji w 6870/50. Trzeba poczekać na 6970/50 które będą się różnić nie tylko wydajnością ale również architekturą względem 68xx. Chyba pierwszy taki przypadek w historii. Czekamy na Caymana i gtx 580 :attack: szał zakupów świątecznych uważam za otwarty XD.

#113
Archiwum / Odp: Nowa obudowa dla mnie
21 Październik 2010, 16:32
Filtry można kupić w byle jakim sklepie za grosze, więc to nie problem.
http://www.cooling.pl/oslonyfiltrygrille,kategoria,31_46.html
http://www.cooling.pl/oslonyfiltrygrille,kategoria,31_46.html
#114
Archiwum / Odp: Dylemat z wyborem zasilacza
21 Październik 2010, 16:27
Bierz Corsair seria AX albo Seasonic seria X






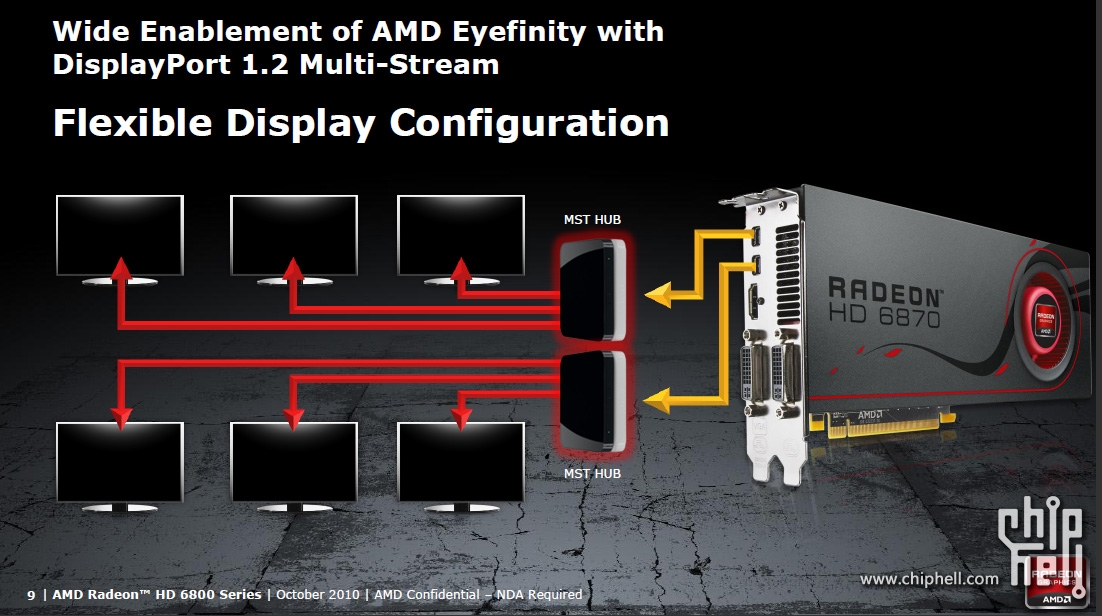

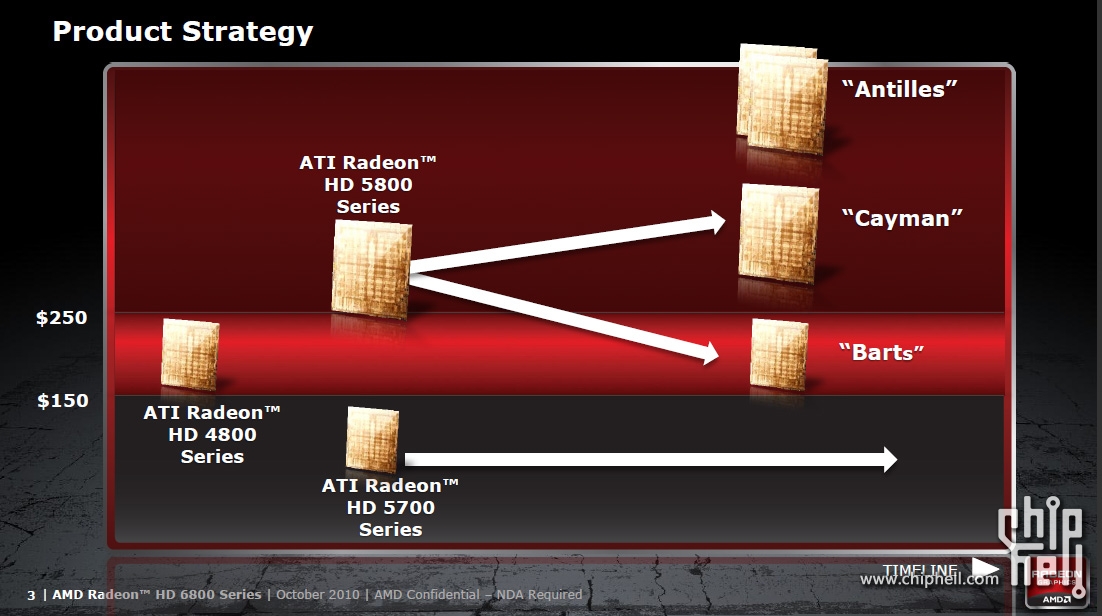
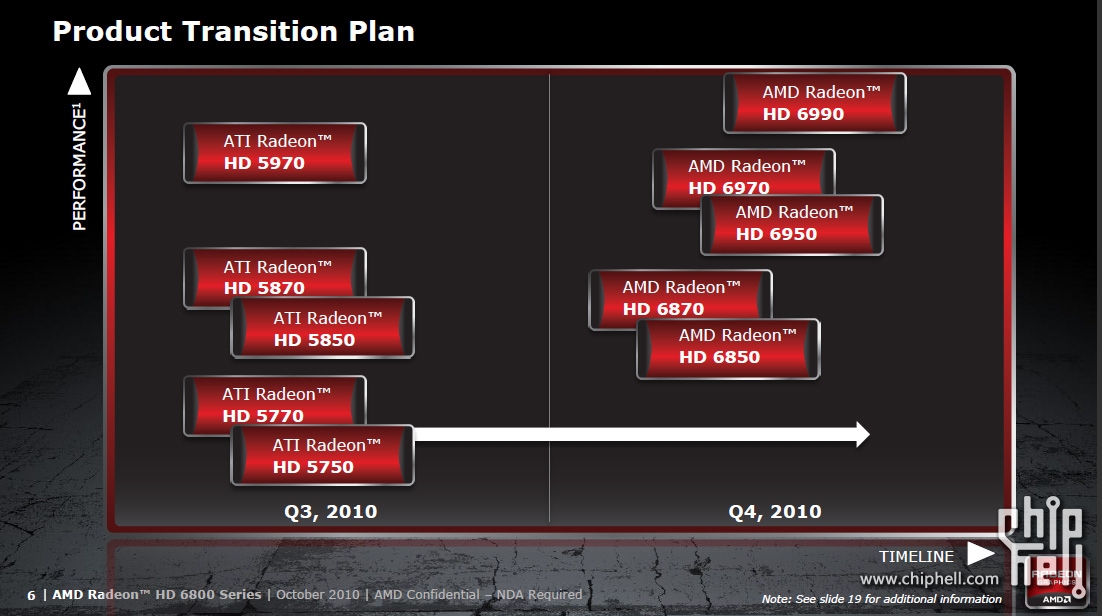


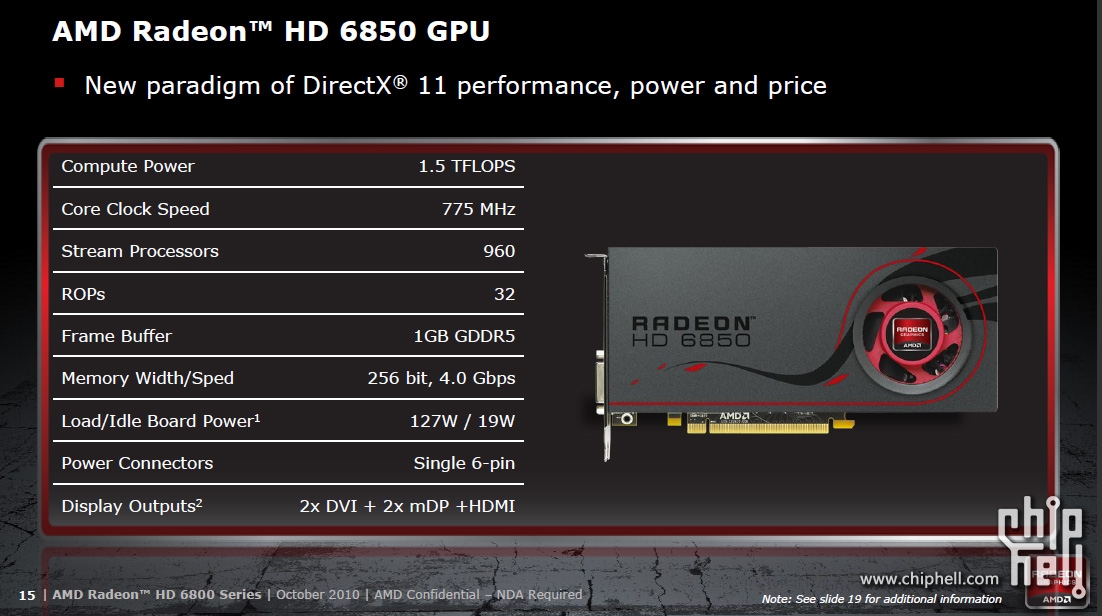




#116
Archiwum / Odp: ATI HD6000 Series
14 Październik 2010, 14:21
Ściśle tajne: ;)


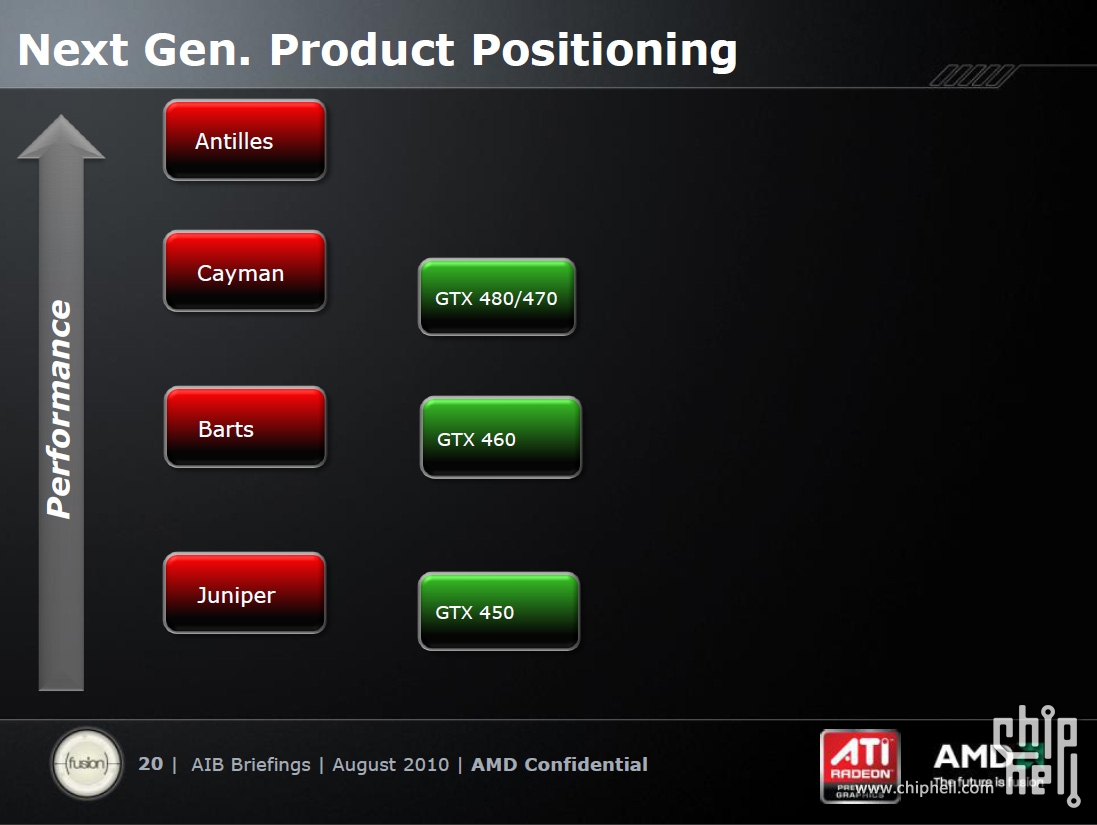
Cała rodzinka do końca roku:

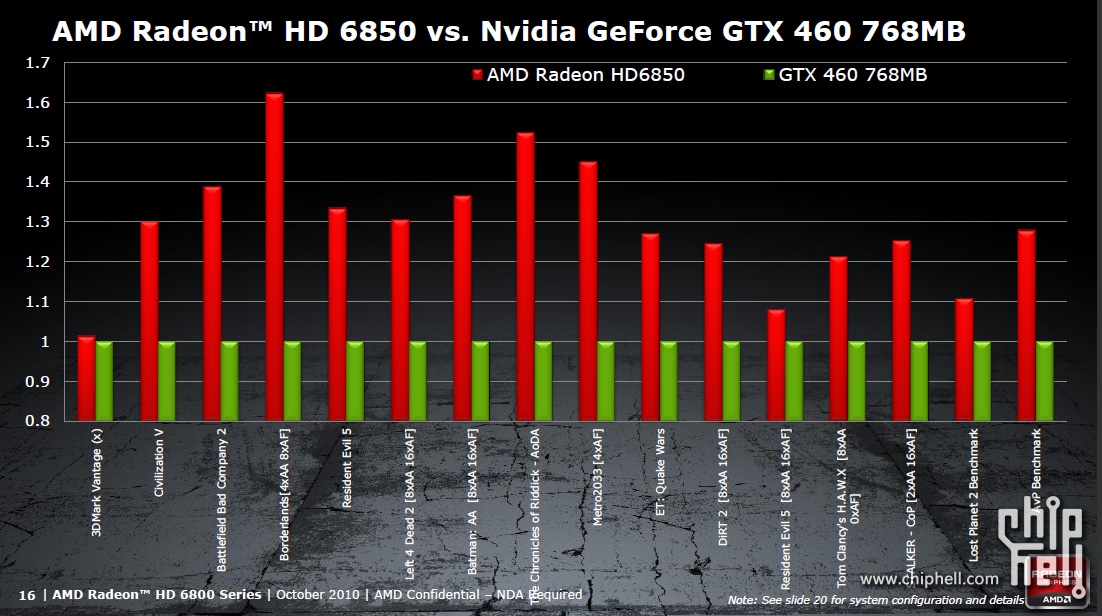
Wydajność względem GTX 4xx:
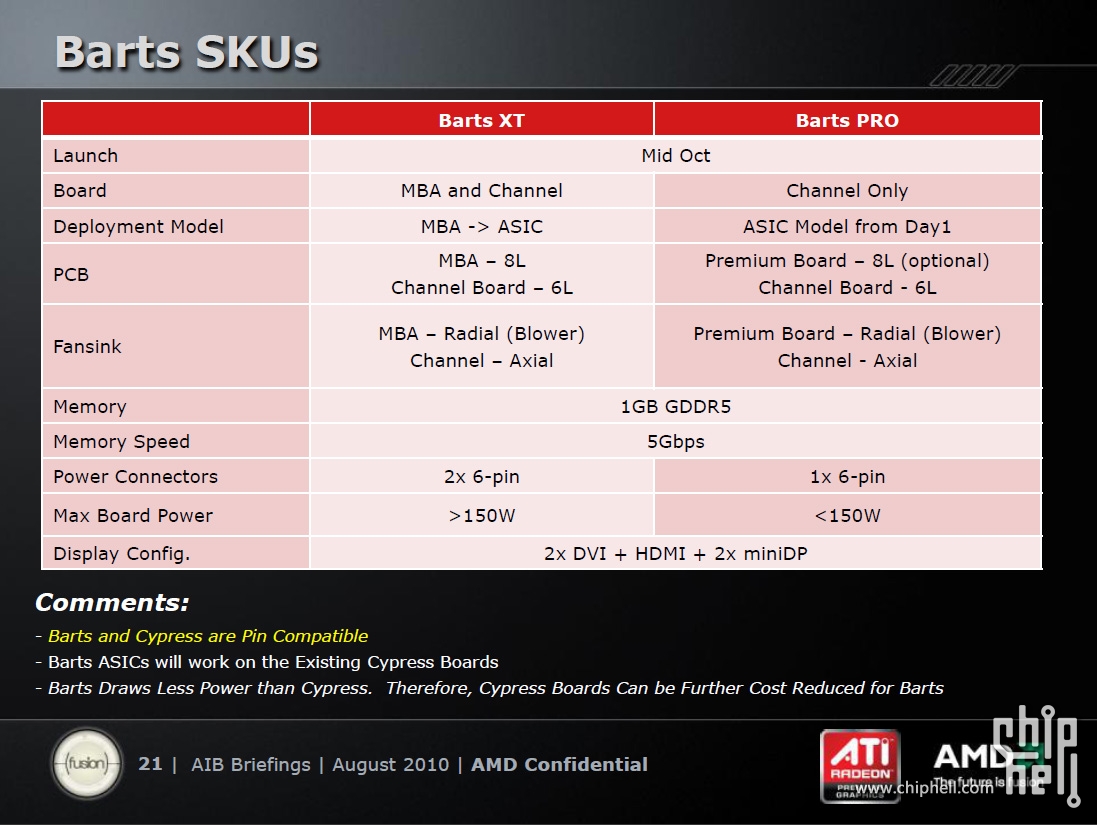
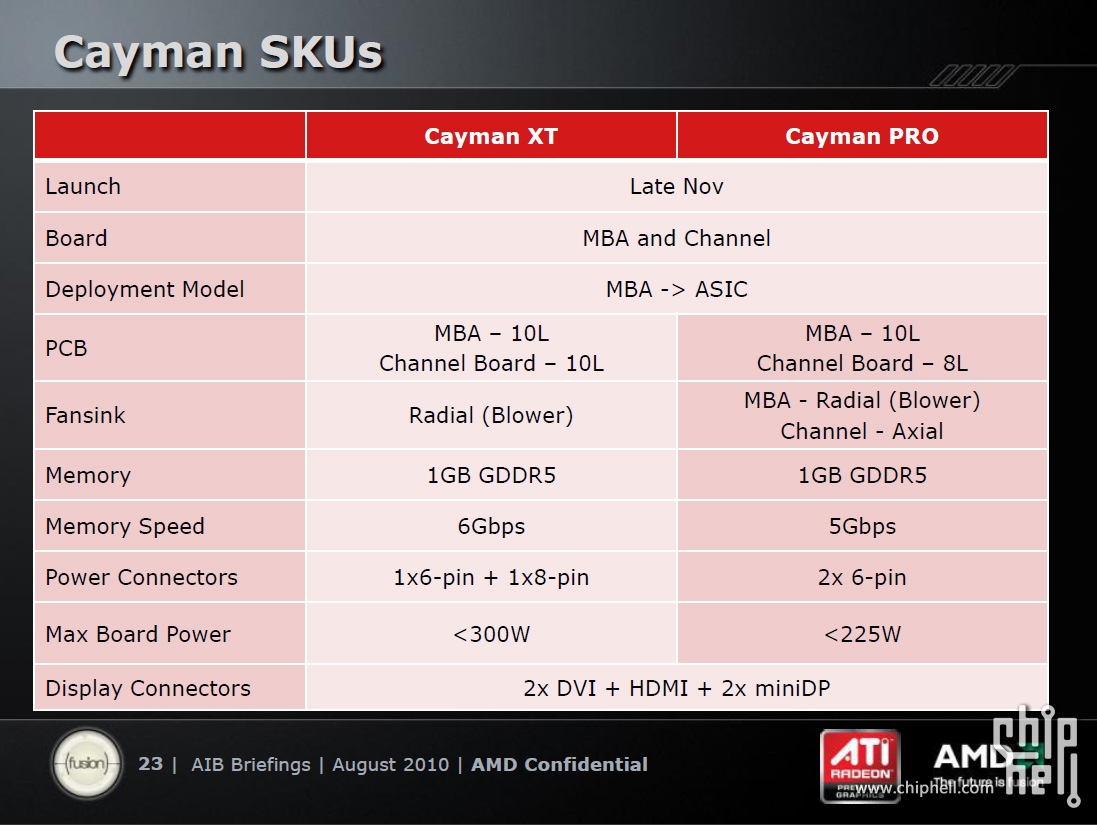
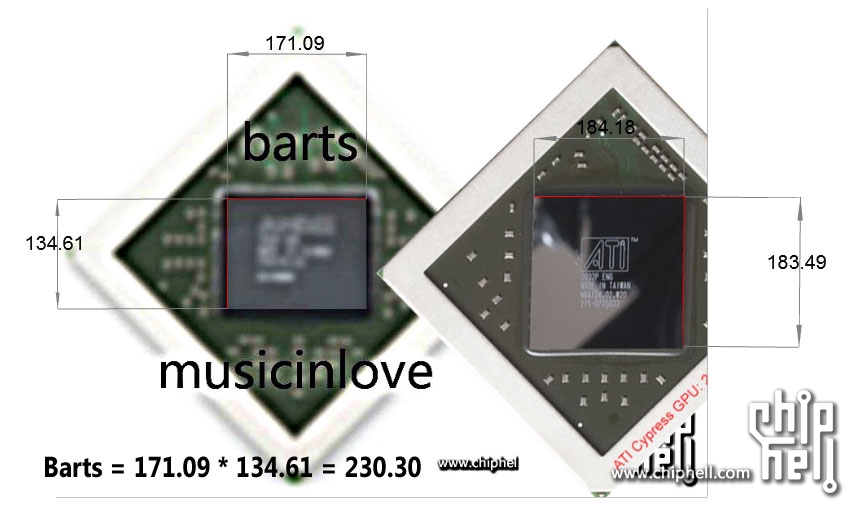
Wielkość 6870/50 (barts): 230mm^2, Cypress 334mm^2, gtx 460 366mm^2, gtx 480 550mm^2
Cała rodzinka do końca roku:
Wydajność względem GTX 4xx:
Wielkość 6870/50 (barts): 230mm^2, Cypress 334mm^2, gtx 460 366mm^2, gtx 480 550mm^2
#117
Archiwum / Odp: D601 w HD4870 - krytyczny problem zasilania rdzenia karty
09 Październik 2010, 21:23
Jak na gpu miałeś 115*C to na sekcji zasilania pewnie było ze 130 i nawet więcej więc karta padła.
#118
Archiwum / Odp: ATI HD6000 Series
09 Październik 2010, 21:02


#119
Archiwum / Odp: ATI HD6000 Series
09 Październik 2010, 12:23Cytat: [PBT] Horpah w 09 Październik 2010, 12:18
jeśli to prawda to oprócz powyższego, chodzi pewnie o zmniejszenie kosztów produkcji na jeden chip, bo będą w niższym procesie produkowane więc więcej chipów da się uzyskać z jednego wafelka krzemu,
Pobór mocy pewnie będą miały mniejszy, może podkręcalność lepszą.
Proces jest ten sam 40nm ale na pewno lepiej go udoskonalili.
#120
Archiwum / Odp: ATI HD6000 Series
09 Październik 2010, 12:20Cytat: Krzysiak_PL_GDA w 09 Październik 2010, 12:11Cytat: Tomasz R. Gwiazda w 09 Październik 2010, 12:04
tak sie zastanawiam.. po co komu te karty skoro ich wydajnosc jest na poziomie 5850 ?
Marketing i lans
Co lepiej brzmi mam starego HD5850 czy mam najnowszego HD6870 ;D XD
głównym kryterium będzie cena, kto kupi 5850 za 900zł jak będzie mógł kupić 6870 (dx9,10 wydajność zbliżona, dx11 dużo lepsza ) za 600,700zł?